§3.2 Linear Algebra
Contents
- §3.2(i) Gaussian Elimination
- §3.2(ii) Gaussian Elimination for a Tridiagonal Matrix
- §3.2(iii) Condition of Linear Systems
- §3.2(iv) Eigenvalues and Eigenvectors
- §3.2(v) Condition of Eigenvalues
- §3.2(vi) Lanczos Tridiagonalization of a Symmetric Matrix
- §3.2(vii) Computation of Eigenvalues
§3.2(i) Gaussian Elimination
To solve the system
| 3.2.1 | |||
with Gaussian elimination, where is a nonsingular matrix and is an vector, we start with the augmented matrix
| 3.2.2 | |||
By repeatedly subtracting multiples of each row from the subsequent rows we obtain a matrix of the form
| 3.2.3 | |||
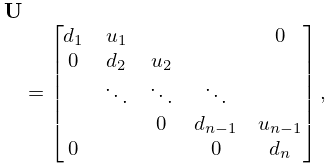
During this reduction process we store the multipliers that are used in each column to eliminate other elements in that column. This yields a lower triangular matrix of the form
| 3.2.4 | |||
If we denote by the upper triangular matrix comprising the elements in (3.2.3), then we have the factorization, or triangular decomposition,
| 3.2.5 | |||
With the process of solution can then be regarded as first solving the equation for (forward elimination), followed by the solution of for (back substitution).
For more details see Golub and Van Loan (1996, pp. 87–100).
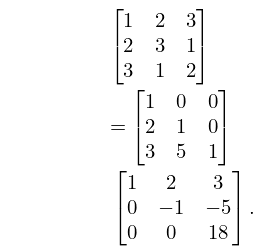
Example
| 3.2.6 | |||
In solving , we obtain by forward elimination , and by back substitution .
In practice, if any of the multipliers are unduly large in magnitude compared with unity, then Gaussian elimination is unstable. To avoid instability the rows are interchanged at each elimination step in such a way that the absolute value of the element that is used as a divisor, the pivot element, is not less than that of the other available elements in its column. Then in all cases. This modification is called Gaussian elimination with partial pivoting.
For more information on pivoting see Golub and Van Loan (1996, pp. 109–123).
Iterative Refinement
When the factorization (3.2.5) is available, the accuracy of the computed solution can be improved with little extra computation. Because of rounding errors, the residual vector is nonzero as a rule. We solve the system for , taking advantage of the existing triangular decomposition of to obtain an improved solution .
§3.2(ii) Gaussian Elimination for a Tridiagonal Matrix
Tridiagonal matrices are ones in which the only nonzero elements occur on the main diagonal and two adjacent diagonals. Thus
| 3.2.7 | |||
Assume that can be factored as in (3.2.5), but without partial pivoting. Then
| 3.2.8 | |||
| 3.2.9 | |||
where , , , and
| 3.2.10 | ||||
| , | ||||
| . | ||||
Forward elimination for solving then becomes ,
| 3.2.11 | |||
| , | |||
and back substitution is , followed by
| 3.2.12 | |||
| . | |||
For more information on solving tridiagonal systems see Golub and Van Loan (1996, pp. 152–160).
§3.2(iii) Condition of Linear Systems
The -norm of a vector is given by
| 3.2.13 | ||||
| , | ||||
The Euclidean norm is the case .
The -norm of a matrix is
| 3.2.14 | |||
The cases , and are the most important:
| 3.2.15 | ||||
where is the largest of the absolute values of the eigenvalues of the matrix ; see §3.2(iv). (We are assuming that the matrix is real; if not is replaced by , the transpose of the complex conjugate of .)
The sensitivity of the solution vector in (3.2.1) to small perturbations in the matrix and the vector is measured by the condition number
| 3.2.16 | |||
where is one of the matrix norms. For any norm (3.2.14) we have . The larger the value , the more ill-conditioned the system.
Let denote a computed solution of the system (3.2.1), with again denoting the residual. Then we have the a posteriori error bound
| 3.2.17 | |||
§3.2(iv) Eigenvalues and Eigenvectors
If is an matrix, then a real or complex number is called an eigenvalue of , and a nonzero vector a corresponding (right) eigenvector, if
| 3.2.18 | |||
A nonzero vector is called a left eigenvector of corresponding to the eigenvalue if or, equivalently, . A normalized eigenvector has Euclidean norm 1; compare (3.2.13) with .
The polynomial
| 3.2.19 | |||
is called the characteristic polynomial of and its zeros are the eigenvalues of . The multiplicity of an eigenvalue is its multiplicity as a zero of the characteristic polynomial (§3.8(i)). To an eigenvalue of multiplicity , there correspond linearly independent eigenvectors provided that is nondefective, that is, has a complete set of linearly independent eigenvectors.
§3.2(v) Condition of Eigenvalues
If is nondefective and is a simple zero of , then the sensitivity of to small perturbations in the matrix is measured by the condition number
| 3.2.20 | |||
where and are the normalized right and left eigenvectors of corresponding to the eigenvalue . Because , where is the angle between and we always have . When is a symmetric matrix, the left and right eigenvectors coincide, yielding , and the calculation of its eigenvalues is a well-conditioned problem.
§3.2(vi) Lanczos Tridiagonalization of a Symmetric Matrix
Let be an symmetric matrix. Define the Lanczos vectors and coefficients and by , a normalized vector (perhaps chosen randomly), , , and for by the recursive scheme
| 3.2.21 | ||||
Then , . The tridiagonal matrix
| 3.2.22 | |||
has the same eigenvalues as . Its characteristic polynomial can be obtained from the recursion
| 3.2.23 | |||
| , | |||
with , .
In the case that the orthogonality condition is replaced by -orthogonality, that is, , , for some positive definite matrix with Cholesky decomposition , then the details change as follows. Start with , vector such that , , . Then for
| 3.2.24 | ||||
For more details see Guan et al. (2007).
For numerical information see Stewart (2001, pp. 347–368).
Lanczos’ method is related to Gauss quadrature considered in §3.5(v). When the matrix is replaced by a scalar , the recurrence relation in the first line of (3.2.21) with is similar to the one in (3.5.30_5). Also, the recurrence relations in (3.2.23) and (3.5.30) are similar, as well as the matrix in (3.2.22) and the Jacobi matrix in (3.5.31).

{kind=link}
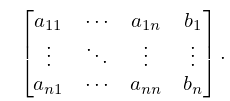{kind=link}
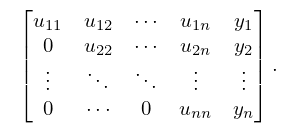{kind=link}
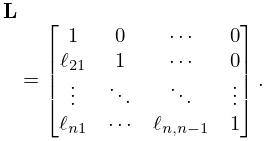{kind=link}
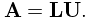{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
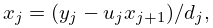{kind=link}
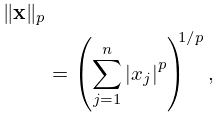{kind=link}
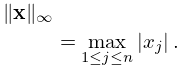{kind=link}
{kind=link}
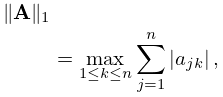{kind=link}
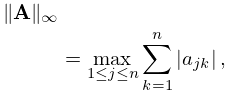{kind=link}
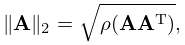{kind=link}
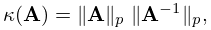{kind=link}
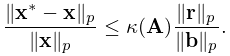{kind=link}
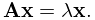{kind=link}
{kind=link}
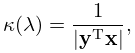{kind=link}
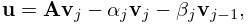{kind=link}
{kind=link}
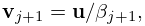{kind=link}
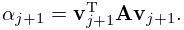{kind=link}
{kind=link}
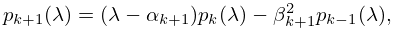{kind=link}
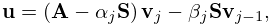{kind=link}
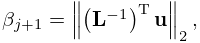{kind=link}
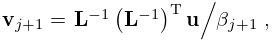{kind=link}
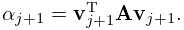{kind=link}